










FrontPage › Project~TitleIndex › Project~NRF_InterdisciplinaryResearch › Project~TwitterResearch › Project~Twitter › Project~Twitter_Pattern
Project »Twitter_Pattern
1. 스케줄 ¶
| 연구일정 | ||
| 6월 | 2주 | 연구계획서 정리, 데이터 수집준비 |
| 3주 | 화이트리스팅 신청,데이터 수집 계획 검토, 프로그램 코딩 | |
| 4주 | 프로그램 코딩 | |
| 5주 | 데이터 수집 준비 완료, 화이트리스팅 등록 | |
| 7월 | 1주 | 데이터 수집 시작, weilbull 분석 준비 |
| 2주 | 데이터 수집, weilbull 분석 준비 | |
| 3주 | 데이터 수집, weilbull 분석 준비 완료 | |
| 4주 | 데이터 수집 완료, weilbull 분석 준비 완료 | |
| 5주 | weilbull 분석을 통한 메시지 패턴 구하기 | |
2. 연구 주제 ¶
- 연구 주제
- '뉴미디어 환경에서의 메시지 확산에 대한 탐구: 트위터 사례분석을 통한 마이크로블로그를 중심으로'
(쉽게말해 트위터에서 메시지가 어떻게 전파되는지 보고싶다!!)
- 마이크로블로그에서 특정 주제에 관한 확산의 패턴과 특징에 관한 탐구
- Weibull distribustion에 따른 메시지 분류해 보고 그 특징과 의미를 찾아본다
- 기존의 확산연구와의 비교를 통해 마이크로블로그가 메시지 확산에 갖는 의미
- 마이크로블로그에서 특정 주제에 관한 확산의 패턴과 특징에 관한 탐구
![[http]](/imgs/http.png) Weibull Distribustion Weibull Distribustion | |
| <그림1>람다값의 변화 | <그림2>누적그래프 |
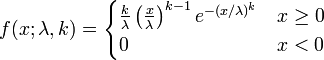
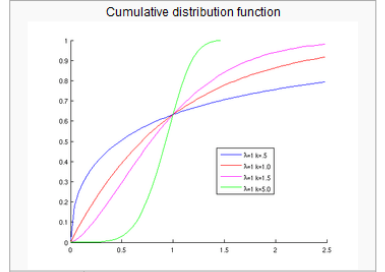
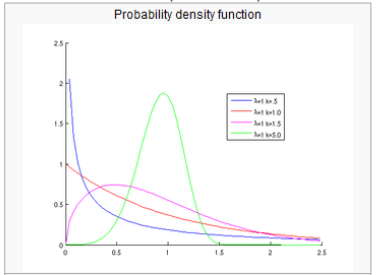
3. 연구 목적 ¶
위의 공식은 연속확률밀도 함수의 하나인 Weibull 분포(distribution)를 만드는 공식으로 앞의 계수 부분 중 케이(k)값은 그래프의 형태를 결정하고, 람다(λ)값은 스케일을 결정한다. 이 곡선은 가로축을 시간으로 생각하고 세로축을 RT의 수라 하면, 메시지가 시간에따른 RT의 분포로 표현할 수 있다. 이를 통해 메시지의 전파 형태를 그려볼 수 있고 형태에 따른 메시지 구분도 가능하게 된다. 덧붙여 위에 제시된 <그림2>과 같은 누적 곡선은 Rogers의 확산이론에 소개된 S곡선도 설명할수도 있다.
본 연구는 메시지가 확산의 경로를 추적하여 메시지 확산 패턴을 구성하고 이 특성에 따라서 메시지들의 성격이나 특성이 어떻게 나누어지는가를 살펴보고자 한다. 구체적으로 Weibull distribution을 이용해 메시지 확산의 패턴을 분류하고 그 군집 별로 어떤 특성이 있는가에 대해서 알아보는 것을 목적으로 한다.
4.1.1. 데이터 수집 사전 준비 ¶
- 장비 준비
- 석혜정 교수님 렌더링 컴퓨터 20대 사용 허락
- 컴퓨터 운영체제 및 IP 확인하기
- (PHP, APAHCE, Mysql) or (JAVA, Eclipse, Oracle)
- Twitter Libraries
- 석혜정 교수님 렌더링 컴퓨터 20대 사용 허락
- API Documents
- White Listing 신청
- White Listing이란?
- 신청양식
- form
 [PNG image (49.98 KB)]
[PNG image (49.98 KB)]
- 데이터 수집 사례
- 카이스트 연구1
- 41.7 million user accounts
- In order to collect user profiles, we began with Perez Hilton who has over one million followers and crawled breadth-first along the direction of follwers and followings. Twitter rate-limits 20,000 requests per hour per whitelisted IP. Using 20 machines with different IPs and self-requlating collection rate at 10,000 requests per hour. To crawl users not connected to the Giant Connected Component of the Twitter network, we additionally collected profiles of theose who refer to trending topics in their tweets from June to August. The final tally of user profiles we collected is 41.7 million.
- 카이스트 연구2
- 54,981,152 user accounts
- These accounts were in-use in August 2009. We obtained the list of user IDs by repeatedly checking all possible IDs from 0 to 80 million. We scanned the list twice at a two week time gap. We did not look beyond 80 million, because no single user in the collected data had a link to a user whose ID was greater than that value.
- 트위터 가입자를 1억 5천명정도로 예상하면 150000000request / (20000request/hour*ip) = 7500 hour*ip
- 7500hour*ip/24=312.5day*ip
- 312.5day*ip / 20ip = 15.625day 적어도 20개의 ip를 사용한다면 15일정도 소요됨.
- Time_zone이나 Location은 사용자가 직접 설정해야 함. => 따라서 전체 트윗에서 Time_Zone이나 Location의 비율을 살펴보고 어느 지역에서 일어난 일인지 짐작하는 것이 합리적일 것이라 생각함.
4.1.2. 데이터 수집 순서 ¶
1. 전체 사용자 기본 데이터 수집=> Numeric ID
2. 지역(미국,한국)에 따른 사용자 추출 => Time_zone
3. 일정 기간 동안 한번도 글을 쓰지 않은 사용자 제거 => UserTimeLine Statuses
4. 사용자 특성(팔로잉,팔로워)에 따른 사용자 집단 세분화 => the number of Following and Follower,the daversity of Media Use
2. 지역(미국,한국)에 따른 사용자 추출 => Time_zone
3. 일정 기간 동안 한번도 글을 쓰지 않은 사용자 제거 => UserTimeLine Statuses
4. 사용자 특성(팔로잉,팔로워)에 따른 사용자 집단 세분화 => the number of Following and Follower,the daversity of Media Use

[PNG image (58.38 KB)]
4.1.2.1. 사용자 수집 ¶
- API: api/user show
- Returns a single status, specified by the id parameter below. The status's author will be returned inline.
Parameters: - API2: api/friends id
- API2: api/followers id
- 대상:
- (데이터 수집일을 기준으로)최근 한달동안 적어도 한 번 포스팅한 사용자
- 사용자의 국적이 미국과 한국인 사용자
- 사용자 정보:
- 사용자 아이디 id
- 사용자 닉네임 screen_name
- 지역 location
- 소개글 description
- 홈페이지 주소 url
- 팔로워 수 followers_count
- 친구수 friends_count
- 가입일 created_at
- 관심지정수 favourites_count
- utc_offset
- 타임존 time_zone
- 트윗수 statuses_count
- 언어 en
- 최근글 status
- 작성시간 created_at
- 글 아이디 id
- 데이터베이스로 정리(msql)
- user_id
| User | ||||
| User ID | Num_Folloing | Num_Follower | Created at | TimeZone(Location) |
4.1.2.2. Tweet 수집 ¶
- API1: api/user_timeline
- Returns the 20 most recent statuses posted from the authenticating user. It's also possible to request another user's timeline via the id parameter. This is the equivalent of the Web /<user> page for your own user, or the profile page for a third party.
- Note: For backwards compatibility reasons, retweets are stripped out of the user_timeline when calling in XML or JSON (they appear with 'RT' in RSS and Atom). If you'd like them included, you can merge them in from statuses retweeted_by_me.
Parameters: - API2: api/retweets
- Returns up to 100 of the first retweets of a given tweet.
Parameters: - 문제: 현재 retweets api를 이용해서는 최근 100개의 retweet만을 얻을 수 있다.
- http://www.mail-archive.com/twitter-development-talk@googlegroups.com/msg18826.html
-개발자포럼
-REST-API-Changelog
-RT이슈들
-트윗통계
- =>차선책??? => ex. http://api.twitter.com/1/statuses/15316085365/retweeted_by/ids.xml?count=100&page=2
- 차선책 tweet단위로 접근(문제는 수집하는 시간이 너무 길어진다는 것,시간이 길어지면 팔로잉,팔로워 수가 수집시점과 전파시점에 차이가 생길 수 있다는 것) => ex. http://api.twitter.com/1/statuses/show/15840409304.xml
- [PNG image (50.6 KB)]
[PNG image (50.6 KB)]
- 대상:
- (데이터 수집일을 기준으로)수집 대상인 사용자들의 최근 한달동안 포스팅된 모든 글: 이때 리트윗한 글은 수집되지 않는다.
- 순수하게 포스팅된 글을 기준으로 리트윗한 글들을 찾아 포함시킨다.
- 데이터베이스로 정리(msql)
- user_id. Optional. Specfies the ID of the user for whom to return the user_timeline. Helpful for disambiguating when a valid user ID is also a valid screen name.
- since_id. Optional. Returns only statuses with an ID greater than (that is, more recent than) the specified ID.
- max_id. Returns only statuses with an ID less than (that is, older than) or equal to the specified ID.
- count. Optional. Specifies the number of statuses to retrieve. May not be greater than 200. (Note the the number of statuses returned may be smaller than the requested count as retweets are stripped out of the result set for backwards compatibility.)
- page. Optional. Specifies the page of results to retrieve. Note: there are pagination limits.
- since_id. Optional. Returns only statuses with an ID greater than (that is, more recent than) the specified ID.
- max_id. Returns only statuses with an ID less than (that is, older than) or equal to the specified ID.
- count. Optional. Specifies the number of statuses to retrieve. May not be greater than 200. (Note the the number of statuses returned may be smaller than the requested count as retweets are stripped out of the result set for backwards compatibility.)
- page. Optional. Specifies the page of results to retrieve. Note: there are pagination limits.
- id. Required. The numerical ID of the tweet you want the retweets of.
- count. Optional. Specifies the number of retweets to retrieve. May not be greater than 100.
- count. Optional. Specifies the number of retweets to retrieve. May not be greater than 100.
| (A)Tweet | |||||||
| Tweet ID | Created at | Media | User ID | Num_RT | Length_RT_Depth | Text | pattern |
| (B)Re-Tweet | |||||
| Tweet ID | Created at | Media | User ID | From_Tweet ID | Current_RT_Depth |
| (A+B)Tweets | |||||||||
| Tweet ID | Created at | Media | User ID | From_Tweet ID | From_User ID | From_Source_Tweet ID | Text | Num_RT | pattern |
- 참고사항:
-Upcoming changes to the way status IDs are sequenced: We are planning to replace our current sequential tweet ID generation routine with a simple, more scalable solution. IDs will still be 64-bit unsigned integers. However, this new solution is no longer guaranteed to generate sequential IDs. Instead IDs will be derived based on time: the most significant bits being sourced from a timestamp and the least significant bits will be effectively random.
-map of a tweet
- API0: search, search2
- Returns tweets that match a specified query.
Parameters:
- since: Optional. Returns tweets with since the given date. Date should be formatted as YYYY-MM-DD
- text:@twitterapi http:\/\/tinyurl.com\/ctrefg
- from_user:jkoum
- id:1478555574
- source: twitter
- created_at:Wed, 08 Apr 2009 19:22:10 +0000
- text:@twitterapi http:\/\/tinyurl.com\/ctrefg
- from_user:jkoum
- id:1478555574
- source: twitter
- created_at:Wed, 08 Apr 2009 19:22:10 +0000
4.1.2.3. Temp ¶
- Twitted message first (with trend)
- Users with the messages
- Trace their social networks
One of the biggest mistake companies and brands make about Twitter is that they think it is one more "shout channel" like TV and Radio and Magazine ads or Press Releases. Twitter is not that. Twitter is a "conversation channel", a place where you can find the audience relevant to you (and your company and products and services and jihad) and engage in a conversation with them. It is not pitching, it is enriching the value of the ecosystem by participating. from
Social Media Analytics: Twitter: Quantitative & Qualitative Metrics ToughTwitter is amongst new media channels that are
![[ISBN-0470529393]](http://images.amazon.com/images/P/0470529393.01.MZZZZZZZ.gif "Amazon:ISBN-0470529393")
![[ISBN-0470562315]](http://images.amazon.com/images/P/0470562315.01.MZZZZZZZ.gif "Amazon:ISBN-0470562315")
6. 참고자료 ¶
Weibull distribution
- http://www.wessa.net/rwasp_fitdistrweibull.wasp?edit=T
- http://www.qualitydigest.com/jan99/html/body_weibull.html
- http://www.dplot.com/registration.htm
- frequently-asked-questions
- 트위터API
- http://www.newwebplatform.com/tips-and-tutorials/Twitter
- http://tweetstats.com/trends | TweetStats;Trends관련 서비스
- http://trendistic.com/ | Trendistic.com
- http://www.flaptor.com/ | Trendistic만든 곳의 홈페이지
- http://www.crowdeye.com | Crowdeye.com
- http://ir.uiowa.edu/polisci_nmp/6/ | The 2009 Philippines Flood and Twitter:Trendistic데이터사용
- http://visitmix.com/Opinions/the-archivist | Twitter Data 관련: Archivist 소개
- http://flotzam.com/archivist/ | Archivist 홈페이지 및 설치
- http://mashable.com/2008/10/02/dipity-public/# | Dipity소개@mashable
- http://www.dipity.com/ | Dipity.com
- http://blog.twitter.com/ | 트위터 블로그
- http://search.twitter.com/about | 트위터 Search 소개
- http://apiwiki.twitter.com/Twitter-Search-API-Method:-search | 트위터 Search API
- http://apiwiki.twitter.com/Libraries#Javanbsp | Twitter JAVA API
- http://www.winterwell.com/software/jtwitter/javadoc/ | Twitter JAVA API 문서
